
老板要求做个招标信息采集工具,方便对过往招标成功案例进行分析,理论上开个会员就能批量将历年数据导出了,但是这个网站的会员好像很贵,而且我们也不需要那么多数据,光是它摆在明面的数据就足以分析一部分内容了,结果内容要导出到excel,那总的来说就是选一个爬虫工具,还有进行excel内容的输出。
爬虫工具选择
其实也没什么选择可以做,本科的时候用了selenium爬取过海岸线异步加载数据,然后经典的爬虫逻辑request+beautifulsoup解析网页结构,但是要爬取的这个网页,其实内容是表格异步加载,通常无法直接使用request获取整个页面的信息。那没法了,只能旧饭重炒。
selenium是基于浏览器内核的自动化框架,其实就是模拟人的操作去获取网页信息,这样如果人在打开网页的时候稍微停顿一下,就能获取表格内容的异步加载了,当然我只能想到这种异步爬取方法,其他更厉害的爬虫手段可能涉及非法爬虫,我也不太敢操作。这个自动化框架是模拟人的操作,所以一定程度上可以规避反爬虫手段。当然麻烦的点就是对应浏览器的驱动安装,首先必须要有浏览器,然后还要找到对应浏览器的内核驱动,这些安装方法其实在网上很多文章,这里也不赘述了。
待爬取网页的分析
网页地址是https://www.bidcenter.com.cn/,但是循路往前搜索发现,比如我要搜索“无人机”,其实主要信息集中在网址:
https://search.bidcenter.com.cn/search?keywords=%e6%97%a0%e4%ba%ba%e6%9c%ba
,这里的keywords=后面的乱码是中文转换的urlcode,当然这里也就提一嘴,实际在后文爬取中,利用浏览器内核会自动转换成urlcode,我一开始不知道还去查了一下如何转换为这种码。话说回来,对上面的这串主信息网址进行分析,发现其url规律很明显,主要是主页地址加上/search?,然后关联keywords,那这样的话,我们可以根据不同要求,在url中替换keywords就能实现对不同关键词的检索结果的请求。
进一步分析,通过chrome的检查工具,锁定我们所需要的表信息集中在<searchlist>中:
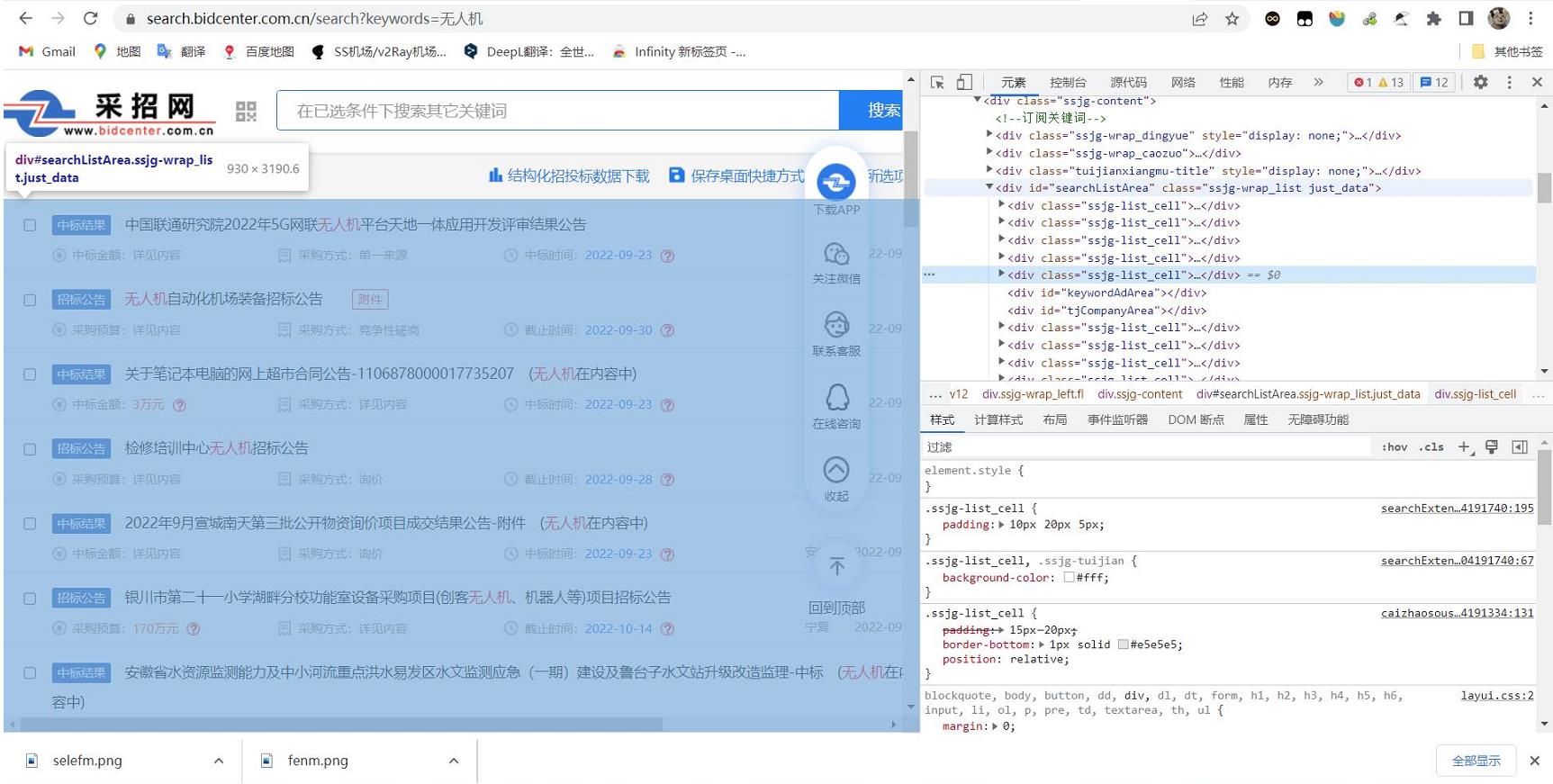
利用xpath可以很轻易地获取这个标签下所有的text文本内容,这样我们复制该标签的xpath,然后利用selenium解析该xpath下的text文本:
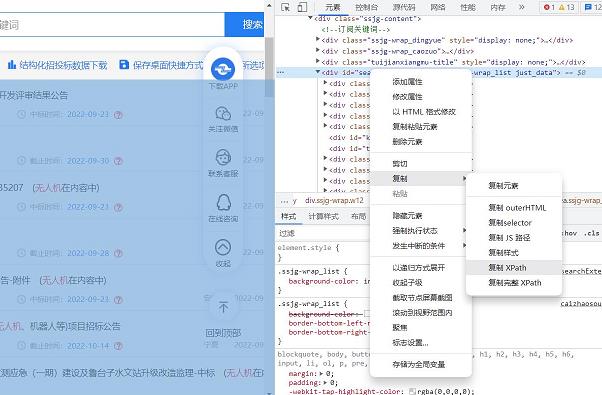
代码编写方法如下:
|
|
到这里,tes内就包含了该表的所有内容。接下来就是繁琐的内容解析归类输出到excel中,但是这个我想放在后文中一块叙述。
多页爬取的方法
上个内容中,我们只爬取了一页,但是实际网页中的内容,是非常多的,一页仅仅显示了40个中标结果,我们想要爬取第二页的内容咋办呢,打开浏览器第二页,观察url的变化,发现url多了一个关联标签page=2:
https://search.bidcenter.com.cn/search?keywords=%E6%97%A0%E4%BA%BA%E6%9C%BA&mod=0&page=2
那方法就很明了了呀,利用python字符串串联的功能,定义两个变量,一个是搜索keywords的变量,一个是page的页数,就能制定自己程序开发时所输入的参数了。
整体爬取函数编写
这里程序的设计思路基本还是比较简单的,我先直接放代码:
|
|
上述代码中,
|
|
三行主要是设置运行时不显示浏览器具体操作,这里注释掉的话可以看浏览器自动化操作的过程。
is_valid_date(strdate)函数主要对日期进行处理,为了判断和正则化日期并保存到excel中,这个函数还是很有必要的。
主函数是crab(),需要的参数在上文中阅读过来的话,应该都很明了了,主要就是关键词和页数,还有csv保存的地方。在selenium解析xpath下的text后,就是多重if判断进行内容的解析,整体程序设计完成。
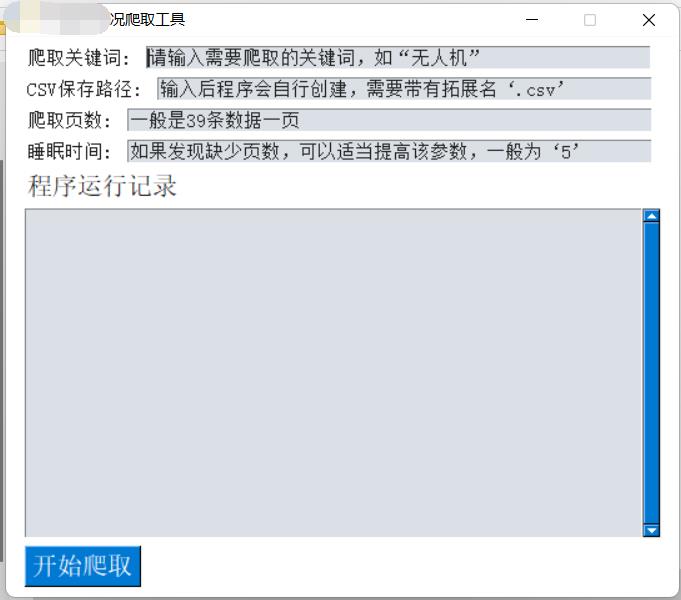
程序界面设计
界面的设计仿造之前的敏捷开发案例,直接修改其中几个控件就能使用,在这里还扩展了一些内容,可以从固定某页爬取到某页,而不是只能从第一页开始爬,比较有趣的地方是这次爬取到csv的信息,爬取完成后程序会帮使用者打开该文件,主要是利用os包完成。
|
|
整体代码
这里给出程序设计的总体代码:
|
|
利用pyinstaller打包以后,程序文件执行结果如下:
总结
selenium爬虫是我本科毕业后第二次接触,但是它本身并不难用,因为是模拟人的浏览器行为,所以很容易能够绕过一些反爬虫手段如异步加载(这我自己也不知道算不算反爬虫),但是如果是用在生产环境的爬虫,其实整体程序环境的布置就很复杂,也是和之前的文章一样,为了方便甲方布置环境是不是得写个.bat?高低都得要。而且为了完整加载页面,这里利用了睡眠机制time.sleep(),人为加长了爬虫时间,那这样超大数据的爬取,比如爬个1000页,那不得几个小时过后了。因此要是真的投入到别的生产环境还是得研究异步加载的其他爬取手段。当然现在这个程序目前也够用,在当下看起来也够高效,那这活也算结束了。