这篇博文是记录我毕业设计的算法的一部分内容,其实也是主要参考了别人的机器学习时间序列预测算法,原本还有个LSTM,但是机子的环境调整不太行,一直运行出error,后续有机会再补上吧。
数据
本次使用的数据是利用实测数据反演叶绿素计算公式的Landsat计算值,实测数据是大二暑假去东北采的了,没想到到了大四能用上,不过我用的是已经做好的反演计算公式,据实验结果反应,反演拟合程度很高,作为论文的一部分内容,我这里不透露具体公式了。遥感数据采用的是1985到2020,经过云量筛选以及影像检查最终选择的Landsat月密度数据,时间跨度很长,数据量很大,总共下载了180多景影像,其实用GEE几乎一天就能出完结果了,但是实际上也是对python开发能力的锻炼,最重要的是我不会javascript,也就是GEE,所以被迫使用本地处理🤣
数据的使用分布如下。
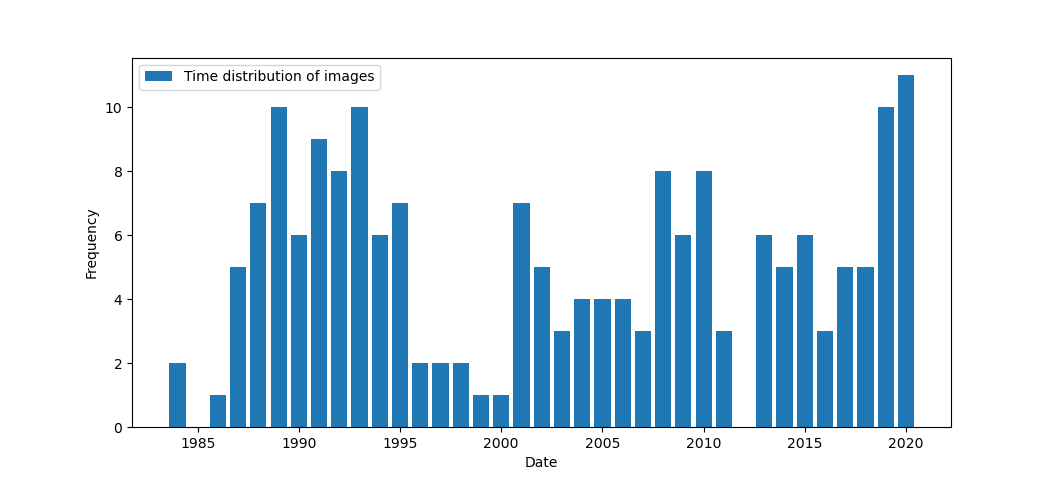
通过批量大气校正和叶绿素计算以后,经过随机点提取后求均值,获取长时间序列的叶绿素变化的列表,存储到csv中后,接下来开始使用xgboost进行时间序列预测
首先导包
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import xgboost as xgb
import glob
from sklearn.metrics import mean_squared_error, mean_absolute_error
from datetime import datetime
import glob
plt.rcParams['font.sans-serif'] = 'SimHei' #显示中文
plt.rcParams['axes.unicode_minus'] = False #显示负号
plt.rcParams['figure.dpi'] = 300 # 图像分辨率
plt.rcParams['text.color'] = 'black' # 文字颜色
plt.style.use('ggplot')
|
拆分测试和验证集
1
2
3
4
5
6
7
8
9
10
11
|
df = pd.read_csv('D:/Pyprogram/veg_data/CCC_Compare.csv')
df['Date'] = pd.to_datetime(df['Date'],format='%Y%m%d')
df.set_index('Date', inplace=True)#索引
shrub = df[['shrub']]
split_date = '2016-01'
shrub_train = shrub.loc[shrub.index <= split_date].copy()
shrub_test = shrub.loc[shrub.index > split_date].copy()
_ = shrub_test.rename(columns={'shrub': 'shrub SET'})\
.join(shrub_train.rename(columns={'shrub': 'TRAINING shrub'}),how='outer') \
.plot(figsize=(20,5), title='shrub CCC', style='.')
|
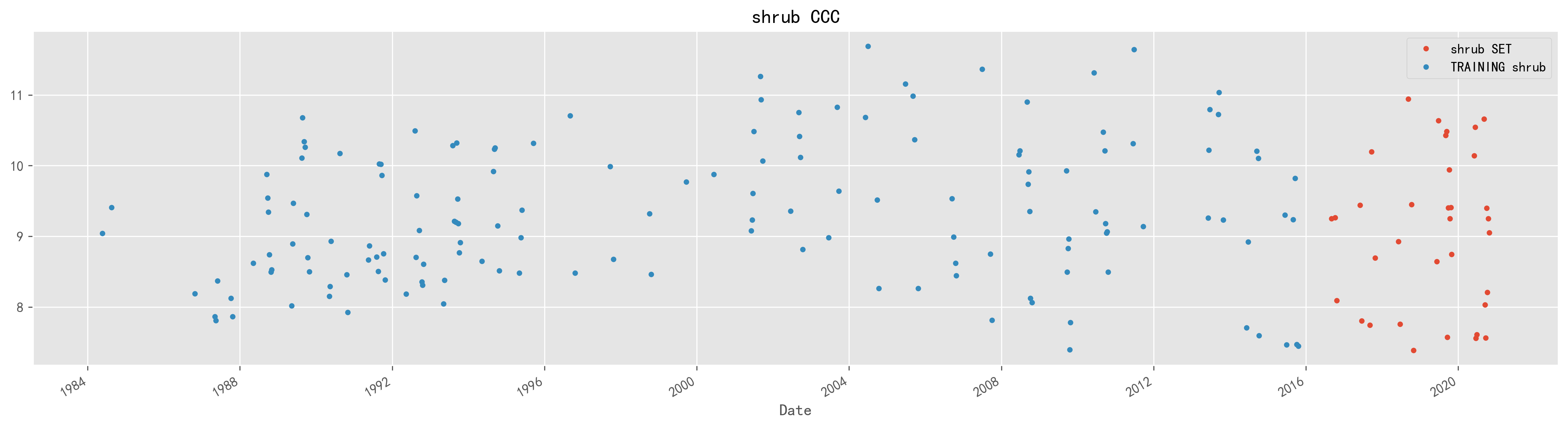
以2016年为时间分界点,拆分数据集,以此之前为测试集,后为测试集,作图如下:
特征工程
创造新的特征是一件十分困难的事情,需要丰富的专业知识和大量的时间。机器学习应用的本质基本上就是特征工程。——Andrew Ng
这里特征选择就以年间隔和月间隔等细分化,作为细化特征输入。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
def create_features(df, label=None):
"""
Creates time series features from datetime index
"""
df['date'] = df.index
df['hour'] = df['date'].dt.hour
df['dayofweek'] = df['date'].dt.dayofweek
df['quarter'] = df['date'].dt.quarter
df['month'] = df['date'].dt.month
df['year'] = df['date'].dt.year
df['dayofyear'] = df['date'].dt.dayofyear
df['dayofmonth'] = df['date'].dt.day
#df['weekofyear'] = df['date'].dt.weekofyear
X = df[['hour','dayofweek','quarter','month','year',
'dayofyear','dayofmonth']]
if label:
y = df[label]
return X, y
return X
|
构建训练器
xgboost的训练器参数非常多,但是据说在机器学习参数的调优对最终结果的优化效果非常有限,所以这里的调优没有进行太多实验,但是背靠实测数据的良好效应,这次预测实际还是取得了不错的效果。
1
2
3
4
5
6
7
8
|
X_train, y_train = create_features(shrub_train, label='shrub')
X_test, y_test = create_features(shrub_test, label='shrub')
reg = xgb.XGBRegressor(n_estimators=1000)
reg.fit(X_train, y_train,
eval_set=[(X_train, y_train), (X_test, y_test)],
early_stopping_rounds=50,
verbose=False) # Change verbose to True if you want to see it train
|
把训练器参数打印出来显示,读者有需要可以对着这些参数慢慢调整:
1
2
3
4
5
6
7
8
|
XGBRegressor(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, gamma=0, gpu_id=-1,
importance_type='gain', interaction_constraints='',
learning_rate=0.300000012, max_delta_step=0, max_depth=6,
min_child_weight=1, missing=nan, monotone_constraints='()',
n_estimators=1000, n_jobs=8, num_parallel_tree=1, random_state=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, subsample=1,
tree_method='exact', validate_parameters=1, verbosity=None)
|
接着用构建预测函数,也是非常简单,讲道理现在机器学习在python的封装真的太人性化了
1
2
3
|
shrub_test['Prediction'] = reg.predict(X_test)
pjme_all = pd.concat([shrub_test, shrub_train], sort=False)
_ = xgb.plot_importance(reg, height=0.9)
|
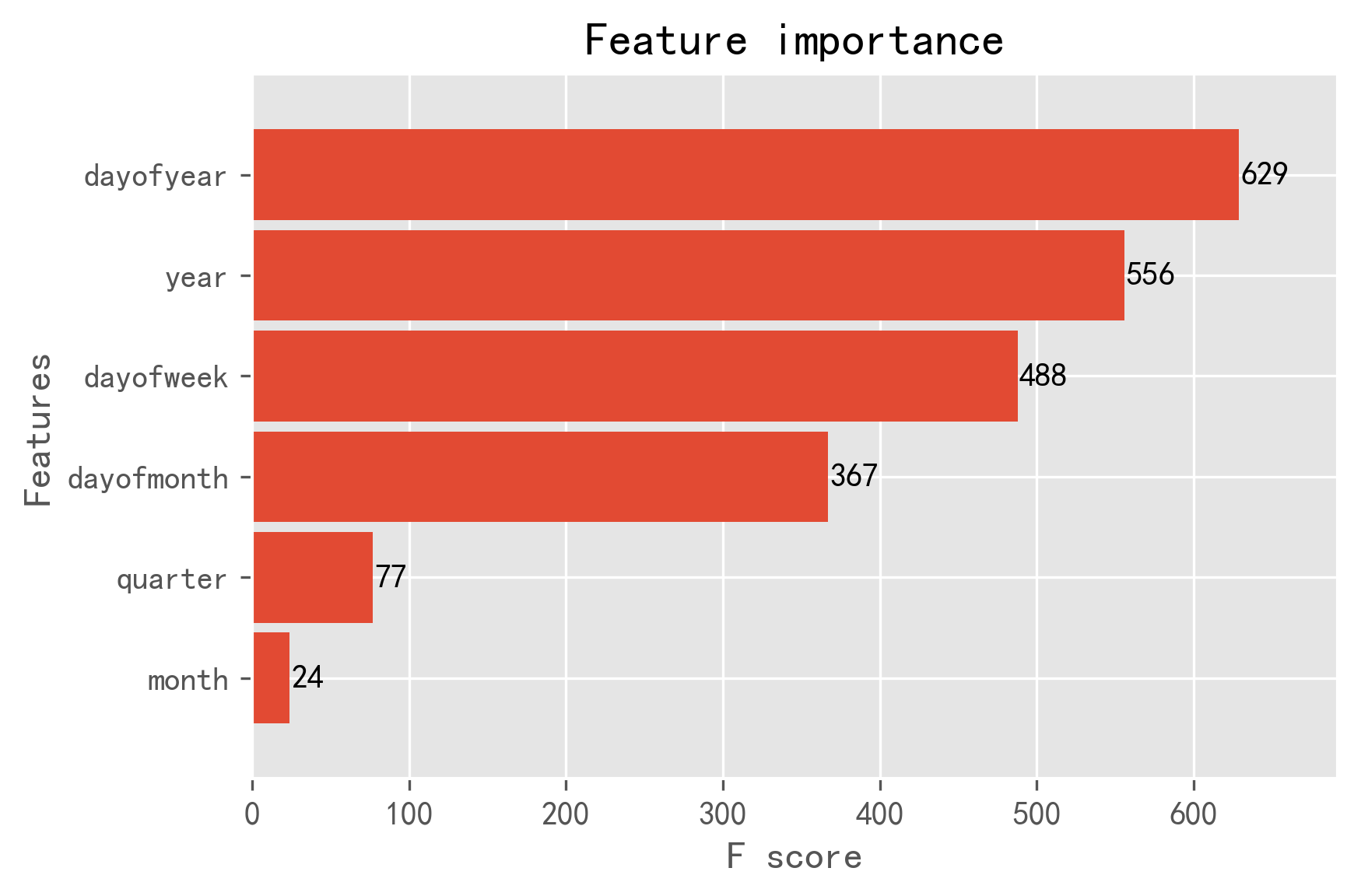
到这里就完成了时间序列预测的大部分工作了。
预测评价指标
更多的研究其实在完成预测后,都需要进行预测误差的评价,这也是之前将数据拆分为测试和验证集的缘由,这里选用的误差评价指标有三种,分别是MAE、MSE、MAPE,其原理在网上都有介绍,这里直接给出计算函数吧,当然除了mape,其他两个都在头文件导入了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
def mean_absolute_percentage_error(y_true, y_pred):
"""Calculates MAPE given y_true and y_pred"""
y_true, y_pred = np.array(y_true), np.array(y_pred)
return np.mean(np.abs((y_true - y_pred) / y_true)) * 100
mse = mean_squared_error(y_true=shrub_test['shrub'], y_pred=shrub_test['Prediction'])
mae = mean_absolute_error(y_true=shrub_test['shrub'], y_pred=shrub_test['Prediction'])
mape = mean_absolute_percentage_error(y_true=shrub_test['shrub'], y_pred=shrub_test['Prediction'])
shrub_test['Prediction'] = reg.predict(X_test)
shrub_all = pd.concat([shrub_test, shrub_train], sort=False)
_ = shrub_all[['shrub','Prediction']].plot(figsize=(15, 5))
|
预测与验证集的可视化:
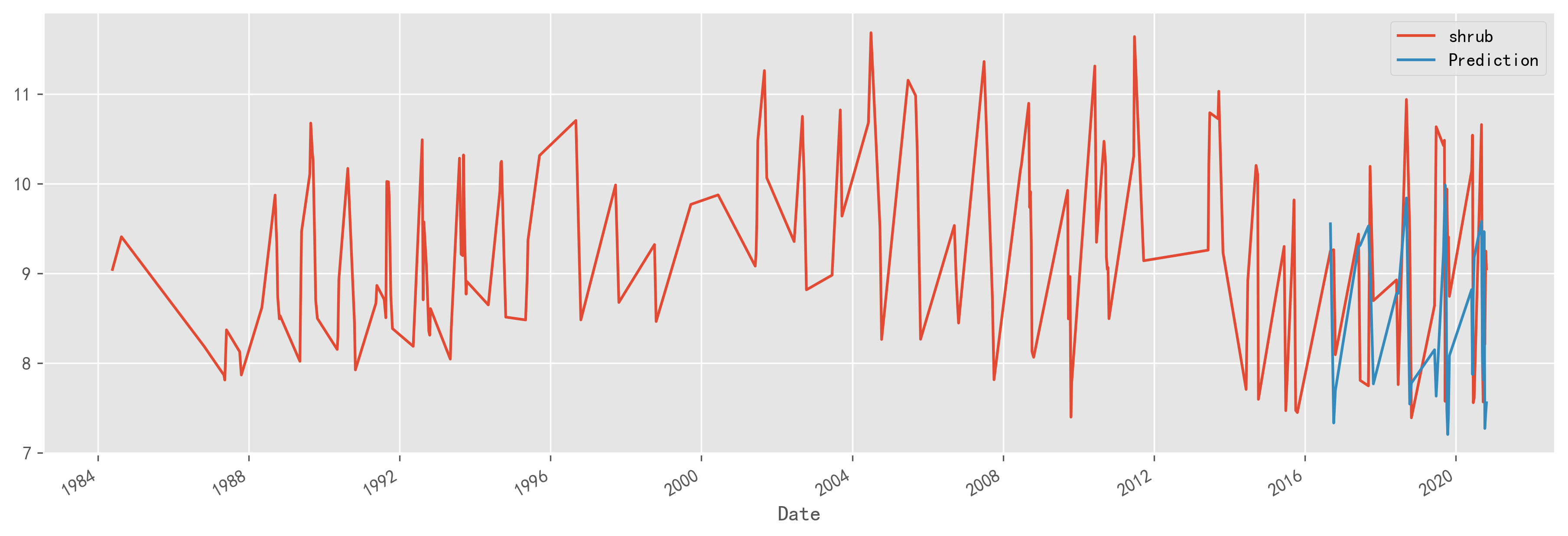 MAE的结果是1.18,基本上预测结果在大范围内还是符合实际情况的,更多的细节就不展示了,主要还是介绍一个xgboost时间序列预测的整体思路。
MAE的结果是1.18,基本上预测结果在大范围内还是符合实际情况的,更多的细节就不展示了,主要还是介绍一个xgboost时间序列预测的整体思路。
后记
这次做叶绿素的时间序列预测,主要能得到的结果比较准确的原因还是因为遥感反演的研究做的扎实,通过反演计算的方法得到的叶绿素值非常精确,其原因也是因为通过实测获取的地面值研究价值很高,所以在预测时,通过调整参数我得到的预测误差减少并不明显。说明遥感时序预测这门学问,还是得在遥感反演下功夫,当然局限于用于机器学习,深度学习时间序列预测还在尝试中,后续可能会写文总结。
